2021 Will Be The Year of AI Hardware
Hardware powering AI is expensive, cumbersome and emits tons of carbon dioxide. There is plenty of room for innovation.

It’s been a while since I’ve published one of these, partly because, well, 2020 and on top of that my topic of choice for the newsletter felt too narrow and restrictive. I’m taking a different approach in 2021. Instead of finding time to write, I want to make time for it. Instead of only focusing on AI ethics (which will continue to feature prominently), I will also write about AI/ML startups, my reflections on building and researching machine learning systems, how AI can help us combat climate change and much more. I hope you will enjoy this renewed and recharged version of Fairly Deep.
In this issue:
I discuss hardware specialized for AI/ML applications and opportunities in that space.
Give an overview of how Nvidia achieved a near-monopoly on ML hardware and why few have successfully challenged it.
Hardware touches every part of the machine learning stack and in the past 10 years there’s been an explosion of research into hardware specialized for ML applications. Such hardware can speed up both training and inference, lower latency, lower power cost and reduce the retail cost of these devices. The current go-to ML hardware solution is the Nvidia GPU, which propelled Nvidia to dominate the market and grew its valuation to be greater than Intel’s. While more and more promising research emerged, Nvidia continued to dominate the space by selling GPUs with its proprietary CUDA toolkit. However, I see four factors that will challenge Nvidia’s dominance and change the ML hardware landscape as soon as this year and certainly in the next 2-3 years:
Academic research in this area is going mainstream.
Moore’s law is dead. With its demise, “technological and market forces are now pushing computing in the opposite direction, making computer processors less general purpose and more specialized.” [source]
Investors and founders alike are realizing that AI can not only break new ground but also their budgets.
AI’s carbon footprint is large and getting larger. We need to make computation more energy efficient.
Background
This is what a typical machine learning pipeline looks like:
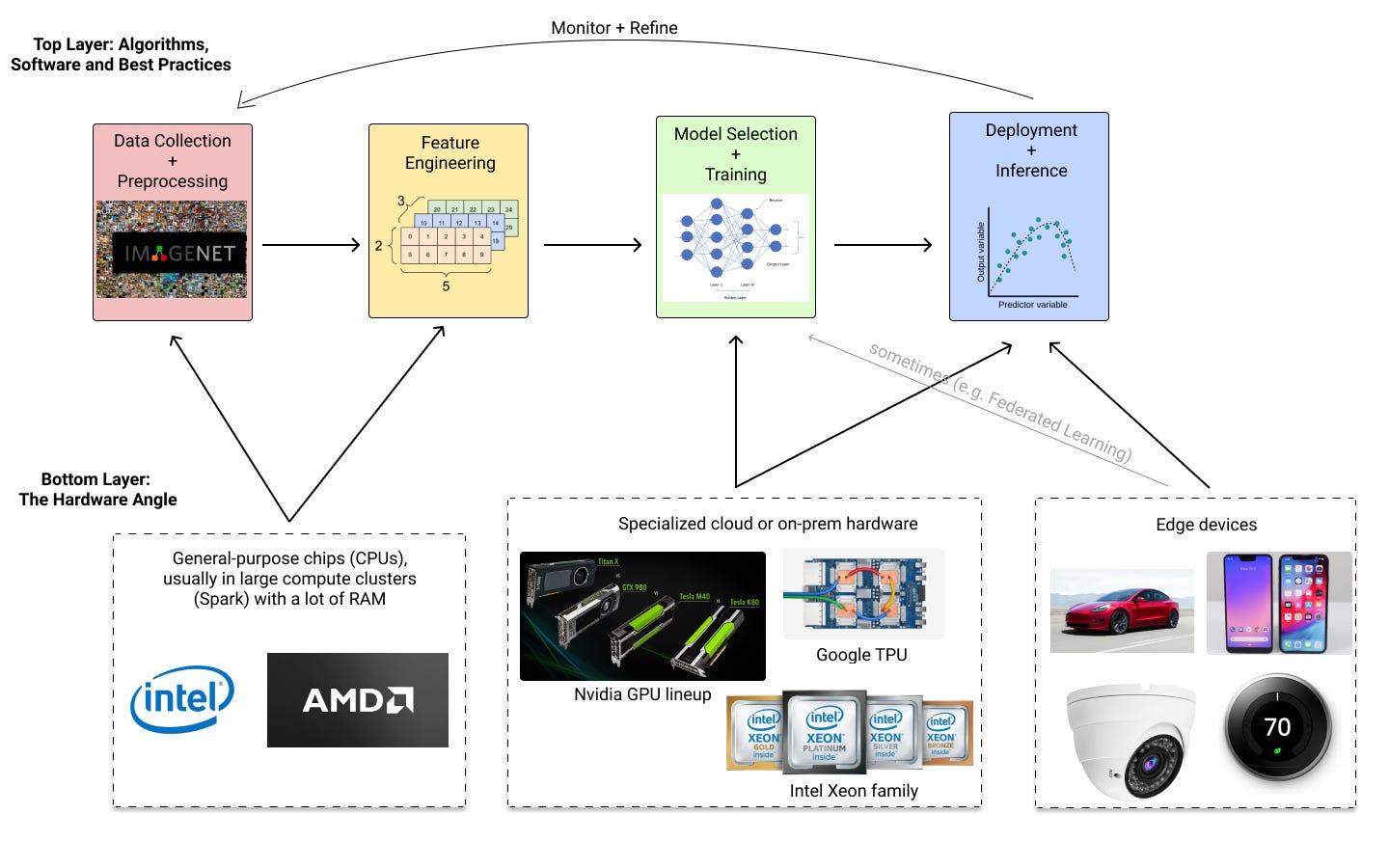
General-purpose chips like CPUs are sufficient for most data science workflows until it comes time to train and deploy large models. For “deep learning,” which involves neural network architectures for tasks like vision and natural language processing, a GPU is almost always necessary. Lambda Labs, a company that provides GPU workstations for deep learning, approximated the cost of training GPT-3 to be around $4.6 million, involving a cluster of Nvidia’s top of the line GPUs.
The primary advantage of using a GPU over the conventional CPU is that it can run computations in parallel with greater data throughput. At its core, the computational part of machine learning is matrix multiplication, which can be greatly sped up when run in parallel. Nvidia’s proprietary CUDA provides both an API and a tool for developers to take advantage of this parallelization. It’s abstracted away by popular libraries like TensorFlow and PyTorch, where one line of code will automatically detect your GPU and then leverage the CUDA backend. If you are designing a brand new algorithm or library and need to take advantage of parallel computation, CUDA provides the tools to make that easier.
Nvidia started in the early 1990s as a video gaming company, wanting to provide graphical chips that could quickly render 3D graphics. It was successful in that business, consistently building some of the most powerful GPUs in a constant back-and-forth with AMD, another graphics card manufacturer. Coincidentally, the same graphics hardware turned out to be indispensable for deep learning to take off. CUDA gave Nvidia an advantage over other GPUs.

Nvidia first released its CUDA toolkit in 2006, providing an API that made it dramatically easier to work with GPUs. Three years later in 2009, Andrew Ng, an AI professor at Stanford, and his collaborators published a paper showing that large-scale deep learning could be made possible if GPUs were used during training. A year later, Ng and Sebastian Thrun, another Stanford professor and later cofounder of Google X, pitched Larry Page the idea for a deep learning research group at Google, which later became Google Brain. With the rise of Google Brain and “the Imagenet moment,” Nvidia’s GPUs became the de facto computing standard for the AI/ML industry. See this article for more.
TLDR: The Status Quo
Nvidia dominates the deep learning hardware landscape with its GPUs, largely due to CUDA. “In May 2019, the top four clouds deployed NVIDIA GPUs in 97.4% of Infrastructure-as-a-Service (IaaS) compute instance types with dedicated accelerators,” according to Forbes. It’s not sitting still in the face of competition either.
Google developed the TPU, an AI accelerator chip specifically made for neural networks, back in 2015. In its narrow use case as a domain-specific accelerator, TPUs are faster and cheaper than GPUs, but they’re walled off within Google’s GCP ecosystem and are supported only by TensorFlow and PyTorch (other libraries need to write their own TPU compilers).
AWS is making a bet on its own silicon, particularly for machine learning. So far, the AWS Inferentia chip appears to be the most successful. Much depends on how easy it will be for developers to switch from CUDA to Amazon’s toolkit for Inferentia and other chips.
In December 2019, Intel bought Habana Labs, an Israeli company that makes chips and hardware accelerators for both training and inference workloads, for $2 billion. Intel’s investment appears to be paying off – last month, AWS announced it will be offering new EC2 instances running Habana’s chips that “deliver up to 40% better price performance than current GPU-based EC2 instances for machine learning workloads.” Intel also has a new line of Xeon CPUs that it thinks can compete with Nvidia’s GPUs.
Xilinx, a publicly traded company that invented the FPGA and recently got into AI accelerator chips, was acquired by AMD in October 2020.
Demand for AI-purposed computing power is accelerating
Changes and Opportunities
As I mentioned in the introduction, my hypothesis is that Nvidia’s dominance will be increasingly challenged and eroded in 2021 and beyond. There are four factors contributing to this:
#1. Academic research turning into real products
A number of startups founded by academic and industry researchers are already working on ML-specific hardware and there is room for more to emerge. Papers published in this space are not just suggesting theoretical guarantees but are showing real hardware prototypes that achieve better metrics than commercially available options. [example 1, example 2 and example 3]
There are many types of chips and hardware accelerators, each of them with its own flourishing research community. To briefly list a few:
Application-Specific Integrated Circuit (ASIC). Examples of ASICs include the Google TPU and AWS Inferentia. It can cost upwards of $50 million to research and produce one, but the marginal cost to produce copies is typically low. ASICs can be designed to have low power consumption without compromising too much on performance.
Field-programmable Gate Array (FPGA). FPGAs are old news to high-frequency traders, but in machine learning examples include Microsoft Brainwave and Intel Arria. It’s cheap to produce one FPGA, but the marginal cost to produce many is higher than that of ASICs.
Neuromorphic computing. This field tries to model the biological structure of the human brain and translate it into hardware. Despite the fact that neuromorphic ideas go back to the 1980s, the field is still in its infancy. There is a good overview paper in Nature.
See this survey paper and pay attention to ISCAS for more
Some promising startups leveraging aforementioned research:
Blaize emerged from stealth in 2019, claiming they developed a fully programmable processor that is low-power and achieves 10x lower latency and “up to 60% greater systems efficiency.”
SambaNova Systems, a startup founded by Stanford professors and former Oracle executives, raised from GV and Intel Capital. It just announced a new product offering that is “a complete, integrated software and hardware systems platform optimized for dataflow from algorithms to silicon.”
Graphcore, a British startup that raised rounds led by Sequoia, Microsoft, BMW and DeepMind’s founders.
#2. Moore’s law is dead. For better or worse, specialized hardware is the future.

Moore’s law predicts that the number of transistors on integrated circuits will double every two years. This has been empirically true since the 1970s and is synonymous with the technological progress we’ve seen since then: the personal computing revolution, improvements in sensors and cameras, the rise of mobile, enough resources to power AI, you name it. The only problem is, Moore’s law is coming to an end, if it hasn’t already. It is no secret that “shrinking chips is getting harder, and the benefits of doing so are not what they were. Last year Jensen Huang, Nvidia’s founder, opined bluntly that ‘Moore’s law isn’t possible any more’,” writes the Economist.
In the MIT Technology Review, MIT Economist Neil Thompson explained that “rather than ‘lifting all boats,’ as Moore’s Law has, by offering ever faster and cheaper chips that were universally available, advances in software and specialized architecture will now start to selectively target specific problems and business opportunities, favoring those with sufficient money and resources.” Some, including Thomspon, argue that this is a negative development because computing hardware will start to fragment into “'fast lane' applications that get powerful customized chips and 'slow lane' applications that get stuck using general purpose chips whose progress fades.”
Distributed computing is often used as a way around this problem: let’s use less powerful and cheaper resources but lots of them. Yet, even this option is getting increasingly expensive (not to mention cumbersome when it comes to the complexity of distributed gradient descent algorithms).
So, what happens next? In 2018, Researchers at CMU published a paper arguing that the private sector’s short-term profitability focus is making it hard to find a general-purpose successor to Moore’s law. They call for a public-private collaboration to create the future of computing hardware.

While I’m not opposed to public-private collaborations (more power to them), I think the future of computing hardware is an ensemble of specialized chips that, when working in unison, account for general-purpose tasks even better than CPUs today. I believe Apple’s transition to its own silicon is a step in this direction – proof that hardware-software integrated systems will outperform traditional chips. Tesla also uses its own hardware for the autopilot. What we need is an influx of new players into the hardware ecosystem so the benefits of specialized chips can be democratized and distributed beyond expensive laptops, cloud servers and cars. (Dare I say... It’s Time to Build?)
#3. Founders and investors are concerned about rising costs
Martin Casado and Matt Bornstein of Andreessen Horowitz published an essay in the beginning of last year where they argued that the business of AI is different from traditional software. At the end of the day, it’s all about the margins: “cloud infrastructure is a substantial – and sometimes hidden – cost for AI companies.” As I mentioned, training AI models can cost thousands of dollars (or millions if you are OpenAI) but the costs don’t stop there. AI systems have to be consistently monitored and improved. If your model was trained “offline,” it is prone to concept drift, which is when the real world data distribution changes over time from the one you trained on. This can happen naturally or adversarially, such as when users try to trick a credit-worthiness algorithm. When that happens, the model has to be retrained.
There’s active research on mitigating concept drift and creating smaller models with the same performance guarantees as existing ones, but that’s content for another post. In the meantime, the industry is moving ahead with larger models and greater spending on compute. Cheaper, specialized AI chips can most certainly lower these costs.
#4. Training large models contributes to climate change

A study from UMass Amherst found that training one off-the-shelf natural language processing model generates as much carbon emissions as a flight from San Francisco to New York. Among the big three cloud providers, only Google gets more than 50% of its data center energy from renewable sources.
I don’t think I need to enumerate the reasons why we might want to decrease AI’s carbon footprint. What I will say is that existing chips are exceedingly power hungry and research shows that other types of hardware accelerators, like FPGAs and ultra low energy chips (e.g. Google TPU Edge), can be more energy efficient for machine learning and other tasks.
Even geography matters when it comes to carbon emissions from AI. Stanford researchers estimated that “running a session in Estonia, which relies overwhelmingly on shale oil, will produce 30 times the volume of carbon as the same session would in Quebec, which relies primarily on hydroelectricity.”
On the horizon
I’ve mentioned hardware for AI, but how about AI for hardware? Google recently filed a patent for “a method for determining a placement for machine learning model operations across multiple hardware devices'' using Reinforcement Learning. One of the researchers behind this patent is Azalea Mirhoseini, who is in charge of ML hardware/systems moonshots at Google Brain.
Thanks for reading. See you soon!